Serverless Chrome on AWS Lambda, the guide that works in 2019 and beyond
Getting Chrome and Puppeteer to work on AWS Lambda is ... tricky. There's many guides, many blogs out there and they're all broken in subtle little ways you won't realize until it's too late.
Outdated versions of Chrome, build packages too big for an AWS Lambda, or silently breaking with an infinite timeout. When you end up trawling through old Github issues looking for clues you know something's wrong.
That was me.
I'm writing this guide as a love letter to my future self. Never again will I fall into this trap. Maybe it helps you too :)
The objective
We're building a serverless screenshot service. It's the TODOapp of the headless serverless Chrome world. Every other guide uses this example :D
You can see my final repo on Github. Disregard the README. A long time ago I used a starter kit that no longer works. Chrome version too old, hangs on newPage.
We'll take screenshots of Instagram posts. Convenient for embedding in emails. You could use a similar setup for testing or to make social sharing thumbnails. Whatever your heart desires.

I built my screenshot Lambda for TechLetterApp. A tool that converts markdown into newsletters.
You will learn about:
- serverless
- AWS Lambdas
- headless Chrome
- Chrome Puppeteer
- uploading to S3
Our Lambda is going to take an Instagram URL, take a screenshot, upload the file to S3, and return the URL.
Init new project
Start a new project. We're going raw, no init scripts. Don't need 😇

Yarn or npm will ask you a bunch of questions about your new project. Answer them and you'll end up with a package.json file.
This is also a great opportunity to run git init.
S3 bucket
Before we begin, you'll need an S3 bucket as well. There is surely a way to create these via Serverless, but I don't know it.
Go into your AWS console, search for S3, create a new bucket and give it a name.
Serverless.yml
We start our project with serverless.yml – the Serverless configuration file. Handles all our AWS setup so we can avoid Amazon's confusing dashboard and avoid clicking around. Also means your configuration and server setup becomes part of your code so it's repeatable and always the same.
Version controlled too 👌
I'm assuming you already have Serverless and have set up your AWS credentials.
Create a serverless.yml file and add this stuff 👇

Here's what it means
- service gives your service a name. Used when constructing endpoints for your Lambdas and such
- provider tells Serverless that we're using AWS and sets some basic config. Which
nodeversion we're using, how much memory we want for Lambdas, the default timeout. - provider/iamRoleStatements configures permissions for our service. Our service needs upload access to S3. Permissions are the most common source of weird bugs and failures in my experience. Best copy from somewhere else :)
- functions specifies our Lambda functions. We have a
screenshot-functionhandled by thehandlermethod insrc/index.js - package specifies service packaging instructions. We're telling Serverless to exclude the local Chromium build just in case it's there.
- plugins Serverless comes with a rich ecosystem of plugins. This is where we specify them. We need
serverless-plugin-chrome - custom lets us add a bunch of configuration. Usually for our plugins. Here we specify some runtime flags for Chrome and tell
serverless-plugin-chrometo make Chrome available to thescreenshot-functionLambda
Other guides will show you different ways of running Chrome. Those are outdated and bad. This is the best approach.
Using serverless-plugin-chrome means you're running a remote cloud version of Chrome instead of packaging the entire binary into your Lambda. Makes deploys faster, the Lambda smaller, and your costs lower. I think.
Don't quote me on the costs 😅
Install dependencies
Next we need to install some libraries.
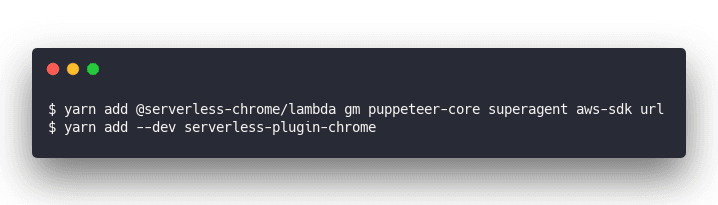
@serverless-chrome/lambda will let us talk to Chrome gm is ImageMagick, we'll use it to resize and optimize images for size puppeteer-core is a minimal version of Puppeteer so we can drive Chrome with JavaScript superagent is a JavaScript library for making requests. We're using it because I copied that part of the code from another guide aws-sdk has a bunch of utilities for talking to AWS. In our case for S3 uploads. url will make it easier for us to parse URLs serverless-plugin-chrome handles all the Chrome stuff for us. We don't have to care 👌
handler.js
Our handler.js file takes care of one thing: Accepting an HTTP request, setting CORS headers, initiating Chrome stuff, calling our code, and responding with an HTTP response.
Looks like this
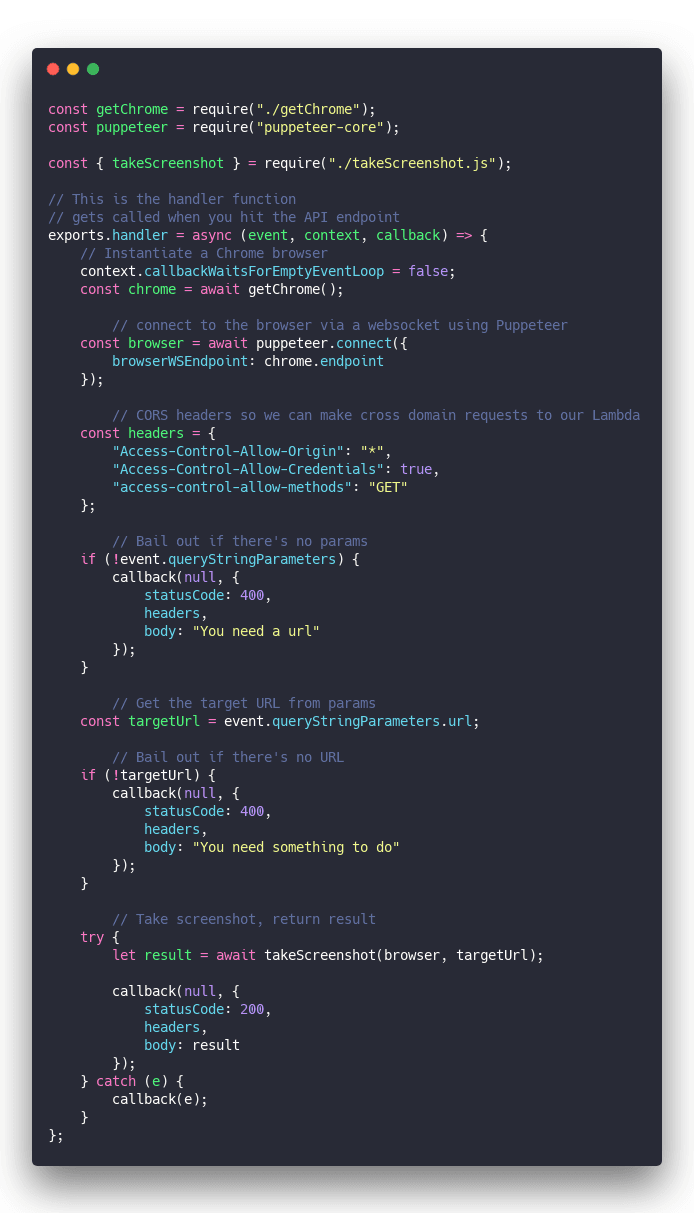
Check the comments above to understand the code. Easier that way :)
So we've got our handler. Let's create the other files.
getChrome.js
I borrowed getChrome from another guide. Good guide but some details didn't work out for me and lead me straight to a sea of GitHub issues.
getChrome makes sure to launch Chrome and return an instance of the browser we can use.

Ask @serverless-chrome/lambda to run the browser and use superagent to get its webSocket URL. We use it in the next step above to connect with Puppeteer.
Great, that's our browser. Nothing packaged into our Lambda making it fat. Wonderful.
takeScreenshot.js
Now the fun stuff, taking a screenshot. I'm gonna explain the code in comments so it's easier to follow 🤓
&t=seti&l=javascript&ds=true&wc=true&wa=true&pv=48px&ph=32px&ln=false&code=const%20URL%20%3D%20require(%22url%22)%3B%0Aconst%20%7B%20uploadScreenshot%20%7D%20%3D%20require(%22.%2FuploadScreenshot%22)%3B%0A%0A%2F%2F%20Async%20takeScreenshot%20function.%20%0A%2F%2F%20Takes%20a%20browser%20instance%20and%20a%20targetUrl%0A%2F%2F%20Returns%20image%20URL%20uploaded%20to%20S3%0Aexports.takeScreenshot%20%3D%20async%20(browser%2C%20targetUrl)%20%3D%3E%20%7B%0A%09%09%2F%2F%20Open%20a%20new%20browser%20page%0A%20%20%20%20const%20page%20%3D%20await%20browser.newPage()%3B%0A%20%20%20%20%2F%2F%20Set%20browser%20size%20to%20something%20decent%2C%20mobile%20mode%20often%20tricks%20websites%20into%20loading%20faster%0A%20%20%20%20await%20page.setViewport(%7B%0A%20%20%20%20%20%20%20%20width%3A%201920%2C%0A%20%20%20%20%20%20%20%20height%3A%201080%2C%0A%20%20%20%20%20%20%20%20isMobile%3A%20true%0A%20%20%20%20%7D)%3B%0A%09%09%0A%09%09%2F%2F%20navigate%20to%20targetUrl%20page%0A%09%09%2F%2F%20wait%20for%20the%20page%20to%20load%20and%20stop%20making%20requests%0A%09%09%2F%2F%20The%20latter%20is%20important%20for%20modern%20SPAs%20that%20render%20after%20document%20is%20loaded%0A%20%20%20%20await%20page.goto(targetUrl%2C%20%7B%0A%20%20%20%20%20%20%20%20waitUntil%3A%20%5B%22domcontentloaded%22%2C%20%22networkidle2%22%5D%0A%20%20%20%20%7D)%3B%0A%0A%0A%20%20%20%20let%20element%20%3D%20null%3B%0A%0A%09%09%2F%2F%20Get%20the%20exact%20DOM%20node%20we%20want%20to%20screenshot%0A%09%09%2F%2F%20This%20is%20where%20you%20can%20keep%20adding%20any%20website%20you%20want%20%3A)%0A%20%20%20%20switch%20(URL.parse(await%20page.url()).hostname)%20%7B%0A%20%20%20%20%20%20%20%20case%20%22www.instagram.com%22%3A%0A%20%20%20%20%20%20%20%20%20%20%20%20element%20%3D%20await%20page.%24(%22article%22)%3B%0A%20%20%20%20%20%20%20%20%20%20%20%20break%3B%0A%20%20%20%20%7D%0A%0A%09%09%2F%2F%20Get%20the%20element's%20dimensions%0A%20%20%20%20const%20%7B%20x%2C%20y%2C%20width%2C%20height%20%7D%20%3D%20await%20element.boundingBox()%3B%0A%0A%09%09%2F%2F%20construct%20a%20new%20filename%0A%20%20%20%20const%20imagePath%20%3D%20%60%2Ftmp%2Fscreenshot-%24%7Bnew%20Date().getTime()%7D.png%60%3B%0A%0A%09%09%2F%2F%20Ask%20Puppeteer%20to%20take%20a%20screenshot%20%0A%09%09%2F%2F%20save%20it%20to%20imagePath%0A%20%20%20%20await%20page.screenshot(%7B%0A%20%20%20%20%20%20%20%20path%3A%20imagePath%2C%0A%20%20%20%20%20%20%20%20clip%3A%20%7B%0A%20%20%20%20%20%20%20%20%20%20%20%20x%3A%20x%20%2B%202%2C%0A%20%20%20%20%20%20%20%20%20%20%20%20y%3A%20y%20%2B%202%2C%0A%20%20%20%20%20%20%20%20%20%20%20%20width%3A%20width%20-%202%2C%0A%20%20%20%20%20%20%20%20%20%20%20%20height%3A%20height%20-%202%0A%20%20%20%20%20%20%20%20%7D%0A%20%20%20%20%7D)%3B%0A%0A%09%09%2F%2F%20upload%20screenshot%20to%20S3%0A%20%20%20%20const%20url%20%3D%20await%20uploadScreenshot(imagePath)%3B%0A%0A%09%09%2F%2F%20return%20the%20result%0A%20%20%20%20return%20url%3B%0A%7D%3B)
In a nutshell, our takeScreenshot function opens a new browser page, navigates to a specific URL, looks for the exact DOM node we want to screenshot, uploads to S3, and returns the result.
I used to try closing the page after screenshotting but that seems to hang sometimes for some websites. Causes problems so it's best to avoid.
Lambdas kill their execution environment, and the browser, after running anyway. Shouldn't be any harm in keeping pages open.
As you can see I wrote this code so it's easy to add other websites. ✌️
uploadScreenshot.js
Last step in the puzzle is uploading our screenshot to S3. You can't host from temporary Lambda files. Gotta put it somewhere permanent.
Again, I'll explain the code inline. Think that's a good approach.
&t=seti&l=javascript&ds=true&wc=true&wa=true&pv=48px&ph=32px&ln=false&code=const%20aws%20%3D%20require(%22aws-sdk%22)%3B%0Aconst%20gm%20%3D%20require(%22gm%22).subClass(%7B%0A%20%20%20%20imageMagick%3A%20true%0A%7D)%3B%0Aconst%20fs%20%3D%20require(%22fs%22)%3B%0A%0A%2F%2F%20Your%20S3%20bucket%20from%20earlier.%20Make%20sure%20you%20use%20the%20same%20name%0Aconst%20BUCKET%20%3D%20%22techletter.app%22%3B%0A%0A%2F%2F%20uploadScreenshot%20takes%20a%20temporary%20file%20path%20and%20returns%20a%20URL%0Aexports.uploadScreenshot%20%3D%20async%20function%20uploadScreenshot(%0A%20%20%20%20path%2C%0A%20%20%20%20resize%20%3D%20true%0A)%20%7B%0A%09%09%2F%2F%20aws-sdk%20is%20all%20callback-based%20so%20we%20have%20to%20wrap%20in%20Promises%2C%20yuck%0A%20%20%20%20return%20new%20Promise((resolve%2C%20reject)%20%3D%3E%20%7B%0A%20%20%20%20%20%20%20%20const%20s3%20%3D%20new%20aws.S3(%7B%0A%20%20%20%20%20%20%20%20%20%20%20%20apiVersion%3A%20%222006-03-01%22%0A%20%20%20%20%20%20%20%20%7D)%3B%0A%0A%20%20%20%20%20%20%20%20if%20(resize)%20%7B%0A%09%09%20%20%20%20%20%20%20%20%2F%2F%20We%20use%20ImageMagick%20to%20resize%20files%20to%20640px%20width%0A%09%09%20%20%20%20%20%20%20%20%2F%2F%20Smaller%20files%20open%20faster%20and%20use%20less%20space%0A%09%09%20%20%20%20%20%20%20%20%2F%2F%20Still%20look%20sharp%20enough%20%3A)%0A%20%20%20%20%20%20%20%20%20%20%20%20gm(path)%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20.resize(640)%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%2F%2F%20make%20sure%20we%20save%20as%20png%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20.toBuffer(%22png%22%2C%20async%20function(err%2C%20buffer)%20%7B%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20if%20(err)%20reject(err)%3B%0A%0A%09%09%09%09%09%09%09%09%09%09%2F%2F%20this%20is%20the%20part%20that%20actually%20uploads%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20const%20%7B%20Location%20%7D%20%3D%20await%20s3%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20.upload(%7B%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20Bucket%3A%20BUCKET%2C%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20Key%3A%20%60screenshot-%24%7Bnew%20Date().getTime()%7D.png%60%2C%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20Body%3A%20buffer%2C%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20ACL%3A%20%22public-read%22%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%7D)%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20.promise()%3B%0A%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20resolve(Location)%3B%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%7D)%3B%0A%20%20%20%20%20%20%20%20%7D%20else%20%7B%0A%09%09%09%09%20%20%20%20%2F%2F%20when%20not%20resizing%20we%20just%20read%20the%20file%20and%20upload%0A%20%20%20%20%20%20%20%20%20%20%20%20(async%20function()%20%7B%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20const%20buffer%20%3D%20await%20new%20Promise((resolve%2C%20reject)%20%3D%3E%20%7B%0A%09%09%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%2F%2F%20reading%20the%20file%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20fs.readFile(path%2C%20(err%2C%20data)%20%3D%3E%20%7B%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20if%20(err)%20reject(err)%3B%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20resolve(data)%3B%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%7D)%3B%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%7D)%3B%0A%0A%09%09%09%09%09%09%09%09%2F%2F%20uploading%20the%20file%20buffer%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20const%20%7B%20Location%20%7D%20%3D%20await%20s3%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20.upload(%7B%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20Bucket%3A%20BUCKET%2C%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20Key%3A%20%60screenshot-%24%7Bnew%20Date().getTime()%7D.png%60%2C%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20Body%3A%20buffer%2C%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20ACL%3A%20%22public-read%22%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%7D)%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20.promise()%3B%0A%0A%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20%20resolve(Location)%3B%0A%20%20%20%20%20%20%20%20%20%20%20%20%7D)()%3B%0A%20%20%20%20%20%20%20%20%7D%0A%20%20%20%20%7D)%3B%0A%7D%3B)
We should now have everything in place to use our Instagram screenshot service.
The very important hack
This is a hack. It's ugly. I found it in GitHub issues. Fixes the "socket hang up" error with Chrome.
Go into your node_modules/@serverless-chrome/lambda/dist/bundle.* files. There's two of them.
In each of those files look for a line like this
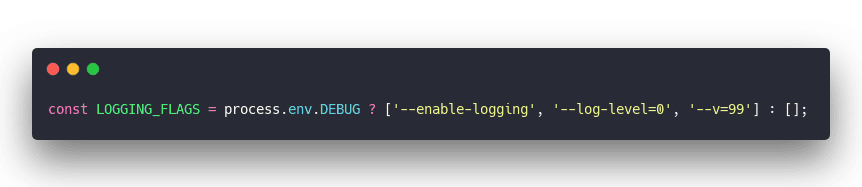
Remove the --v=99 part

You have to do this every time you run Yarn or reinstall anything for any reason
Yes it sucks. Yes I should make an upstream PR. But doing it yourself unblocks you and makes your Lambda work right now.
I have no idea why that breaks it.
Another option might be to remove the DEBUG flag in your serverless.yml ... but then how will you debug?
And, deploy :)

Serverless packages your lambda, deploys to AWS, sets everything up for you, and returns a URL.
That URL is your API endpoint. Call it with an Instagram URL and behold your wonderful screenshots.

I wrapped mine in a nice UI. You can try it at TechLetter.App
PS: I'm working on new education materials, workshops, course and such for serverless, lambdas, full stack React, GraphQL, and Gatsby. Hit reply if you're interested or ping me on Twitter.
Filed under: Back EndTechnical
