90% of performance is data access patterns
If you want a fast app focus on your data patterns. Here's a war story from production.
"Emergency meeting! WTF is your client doing to our servers!?"
The platform team had been chasing a performance bug for weeks. It looked like API requests hogging resources and making the whole system slow even for unrelated requests.
This is an issue that happens on Nodejs servers due to how JavaScript's event loop works. The single-thread single-process model is great at parallelizing IO tasks with lots of waiting, but tends to get stuck on computation. Even a quick algorithm can block the event loop and force all requests to wait.
Platform suspected this was happening and built a visualization of slow API requests combined with their frequency. My team was at the top of the list 😅
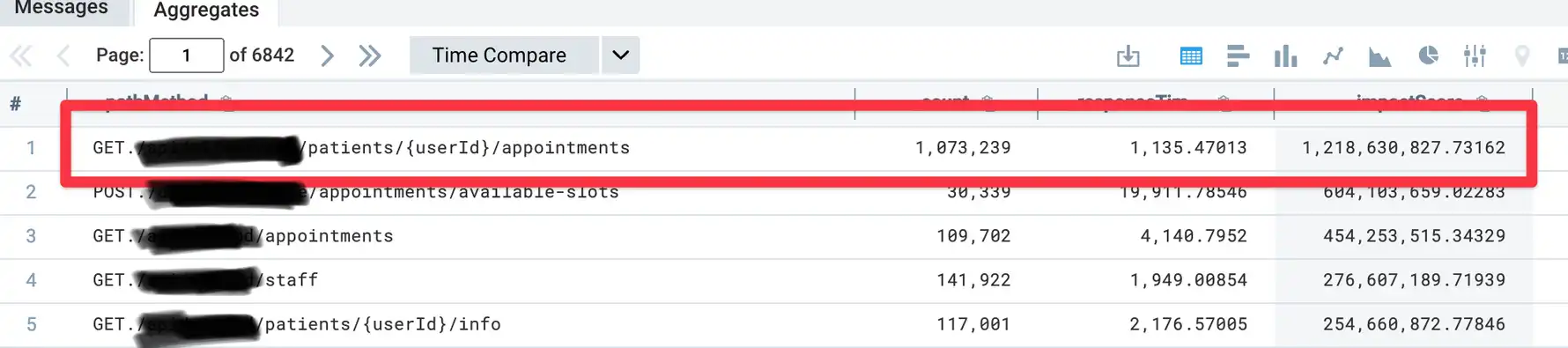
That's 1,000,000+ requests per week loading all of a patient's appointment history. You have to understand how wild that is. The company had around 30,000 patients at the time, most of whom access the patient portal once a week at best.
So why do we keep loading their history? Why do the slowest 5% of requests take over 1.1 seconds? (p95 latency)
Old sins come back
At this point I remembered an old joke we used to say – "Haha isn't it funny how our backend-for-frontend loads appointments on every request".
Waitaminute, surely we're not doing that?
And there it was: Deep in our session middleware, an old performance optimization linked to a 2 year old bug report where someone found this and could not yet remove.
Those jokes you share around when everyone's chill and it's time to gripe, they matter. They are your lore. The myths based on nuggets of truth. And sometimes they tell you where to find the dragon.
Before we had our current infrastructure, before there was even much of a team, a sole engineer faced a problem: Appointments were slow to load and the UI suffered. But the data was small and the time was short. "Cache this in the session", they thought and moved on with their day.
The middleware would fetch all appointments, put them in the session, and all code could read that variable. This worked fine. For years!
Problems change with scale
The home-made caching approach worked when we had few users, little data, and every engineer knew the whole system.
Back when we used a traditional webpage approach it even made sense! Putting data in the session means you're not hitting a slow API multiple times per page. Originally we may have cached across requests, but that has since been lost.
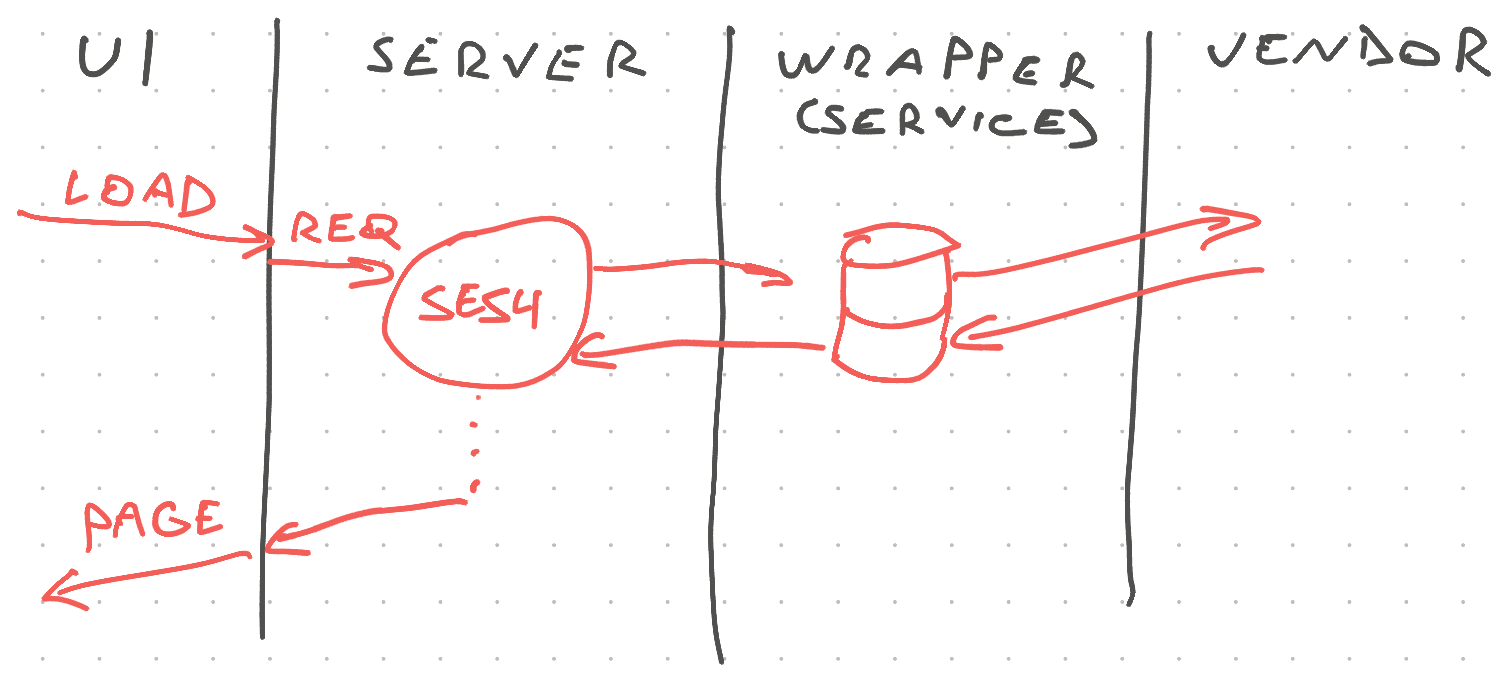
Despite the lack of cross-request caching on the frontend server, things worked fine thanks to our internal service caching data in the database. Running a SQL query for the rich data you need is much faster than hand-holding a series of slow vendor requests.
But then the client app started to grow more complex as our user expectations grew. We went from a series of basic webpages to a rich single-page application hitting our servers with API requests for all sorts of data.
All those requests had to hit the session middleware to verify authentication. The same session middleware that fetched, and then ignored, all appointments.
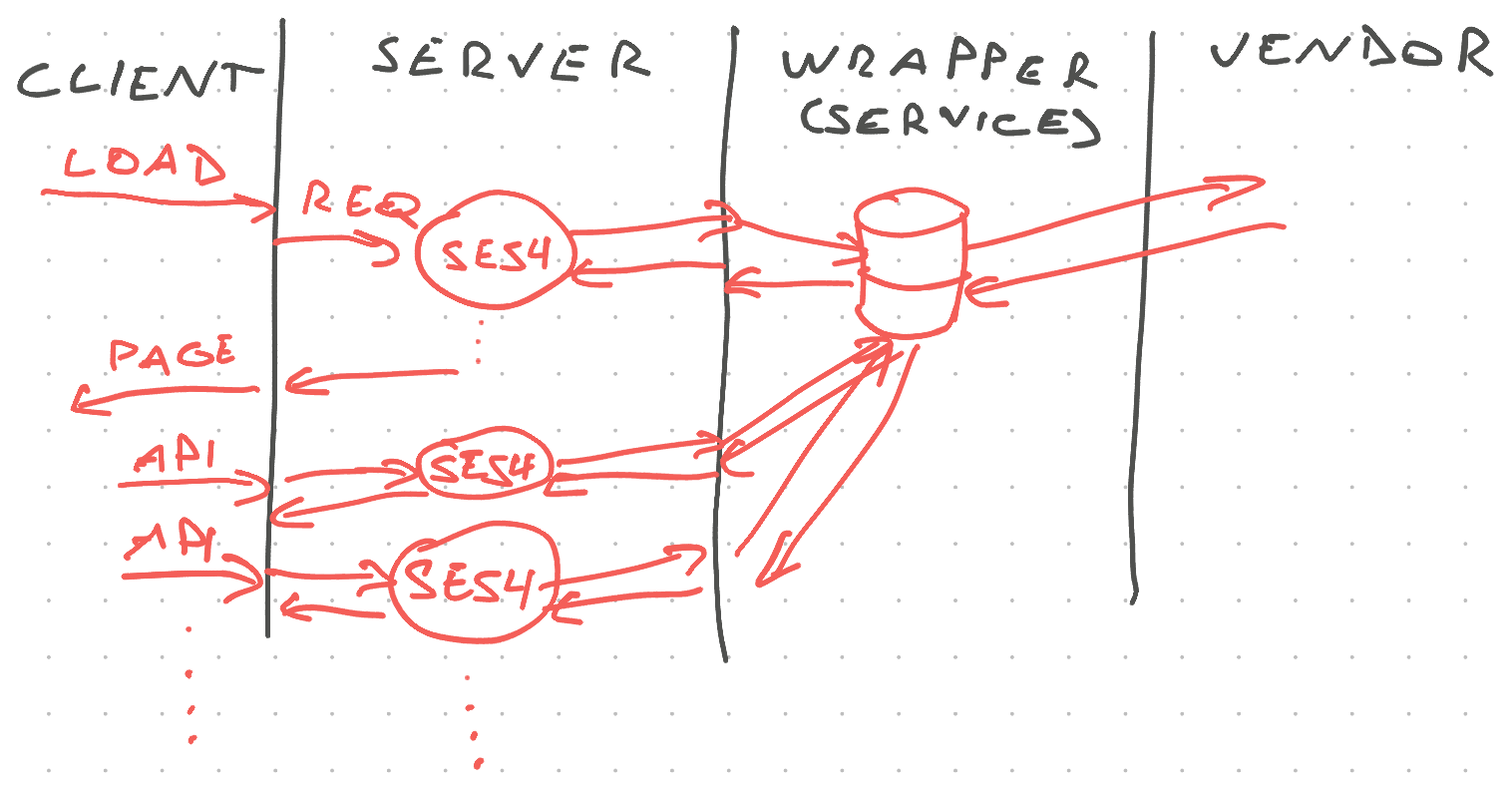
The internal caching layer kept us afloat.
Except as usage grew, all those database reads started putting a strain on the system. The database struggled with frequent memory thrashing and the code struggled to keep processing all the payloads. Everything got slow.
[side-note] Databases internally try to keep frequently used data in memory. When you have lots of queries reading the same data, this works great. When you start having lots of queries for distinct chunks of data, the database can fall into a thrashing pattern where it's constantly moving data between disk and memory. This is slow.
The system will tell you where it hurts
That visualization of slow requests was the system telling us where it hurts: Constantly fetching patient appointments.
After analyzing the code we found that nobody even uses this data anymore! The client uses its own API method to explicitly fetch appointments. Once.
We deleted 1 line of code and CPU usage on our central database dropped by 66%.
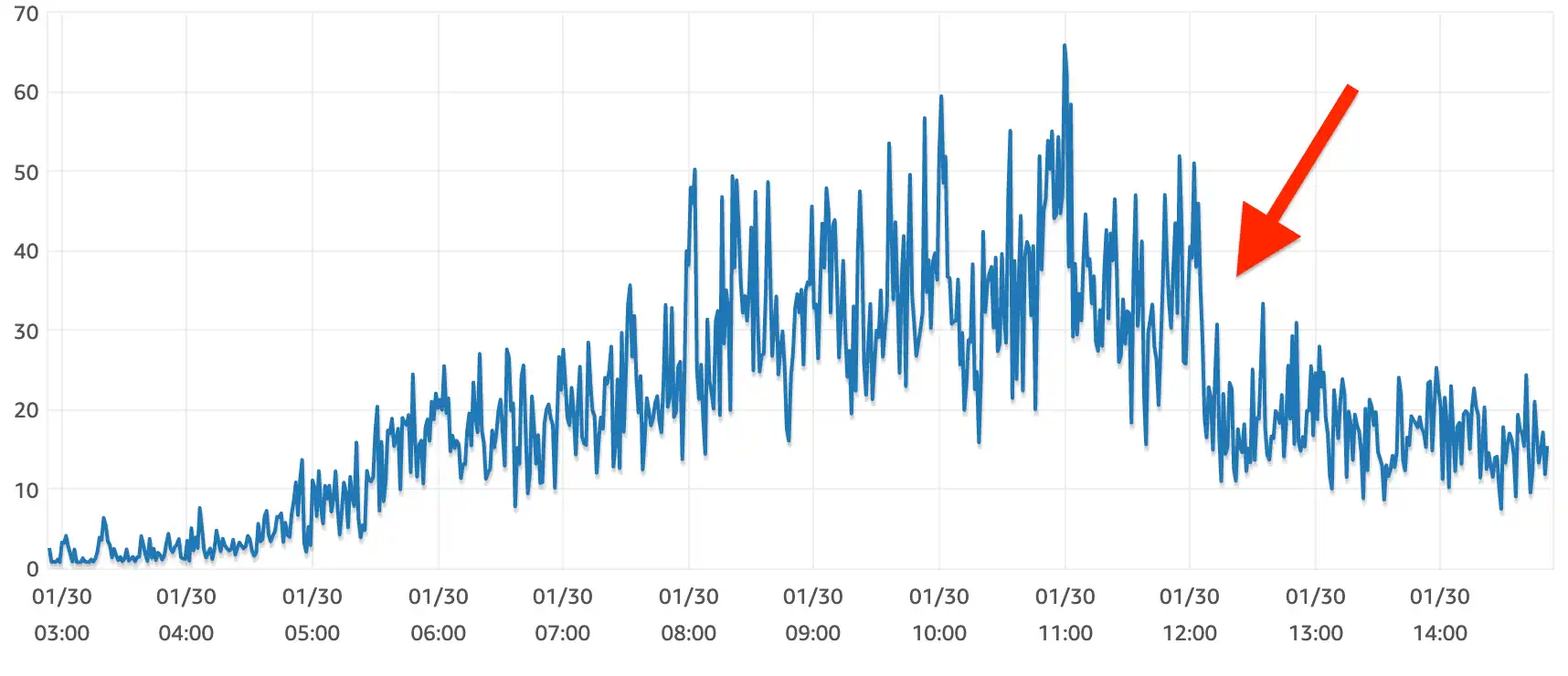
We went from calling that endpoint 150,000x/day to 1,000x/day and the p95 latency dropped by half (slowest 5% of requests took more than 500ms instead of 1s). Latency improved on all other API requests because we stopped hogging the event loop.
This server-side change is my biggest ever React app performance improvement. It made everything feel snappier.
You can't prevent mistakes, but you can invest in observability
Mistakes happen. You can't expect a towering pile of abstractions across dozens of repositories, hundreds of files, millions lines of code, a few years, and a few dozen engineers to stay internally consistent forever. You're going to miss things.
You build a thing that works today and forget about it while the code keeps doing its thing. A few years later there's a bug and someone makes a fix they didn't fully understand. Then you add a bunch of scale and things break in new interesting ways the original creator never could have predicted.
The lesson here isn't that years ago we wrote bad code or that those engineers didn't know what they were doing. The code was good when it happened and the engineers did their best.
The lesson is that the environment changed, it always does, and observability helped us identify a simmering issue before it became an outage. That's a win.
Cheers,
~Swizec
Filed under: Software EngineeringScalabilityObservabilityScaling Fast Book

