


I've been playing around with React's new Concurrent Mode and it is amazing. A little mind-bendy, a dash mad, and a whole lot of wonderful.

Your app might get faster even if you don't change anything. 👌
That's because concurrent mode is backwards compatible. Your code works the same ... if you've been following React best practices. If you haven't, god help you.

So what is concurrent mode?
It's a change in how React schedules updates to your UI.
/../ UI libraries, including React, typically work today. Once they start rendering an update, including creating new DOM nodes and running the code inside components, they can’t interrupt this work. We’ll call this approach “blocking rendering”. In Concurrent Mode, rendering is not blocking. It is interruptible. This improves the user experience. It also unlocks new features that weren’t possible before.
What this means is that you can start new UI updates before the old ones finish.
Say you're building a dataviz with streaming data. You're 5,000 elements in so adding another 1,000 takes a while. You start rendering and a new batch shows up before you're done.
Now what?
With blocking renders you have to wait.
With concurrent mode you stop the current render and schedule a new one. 👌
It's similar to how D3 transitions always let you schedule a new transition without worry. Each new transition first stops whatever's going on, then starts the new transition from current state.
Try clicking this ball real fast to see what I mean

Not quite concurrent mode but a similar idea.
Ok so what?
So what!? This is amazing. This is what we've been waiting for for 2 years my friend.
Not only is concurrent mode a big step forward for React itself, it also gives us some new abilities. The community is still figuring out the details, but what I've seen buzzing on twitter looks exciting.
My favorite new ability is React Suspense for data fetching. Dan just published an example where he loads code for the page at the same time as its data. And then concurrent mode figures out the rest.


Various react routes will have to implement this to work properly. You can't quite do it unless you know what data you'll need before your components render.
That's the biggest shift in mindset: Fetch data before/while rendering. Not after initial render like we used to:

Dunno about you, but I'm tired of writing that code. Fingers crossed we get some amazing new libraries around Suspense. 🤞
While we wait, here's some concurrent mode stuff you can do right now.
Trying concurrent mode yourself
The easiest way to try concurrent mode is to fire up a CodeSandbox and choose React's experimental channel.

Same thing works in your package.json. Please don't use it in production yet. Experiment and play only. There's bugs to fix and features to come :)
We played around on a recent livestream and created a couple tiny examples using React Suspense's new fetch-as-you-render ability.

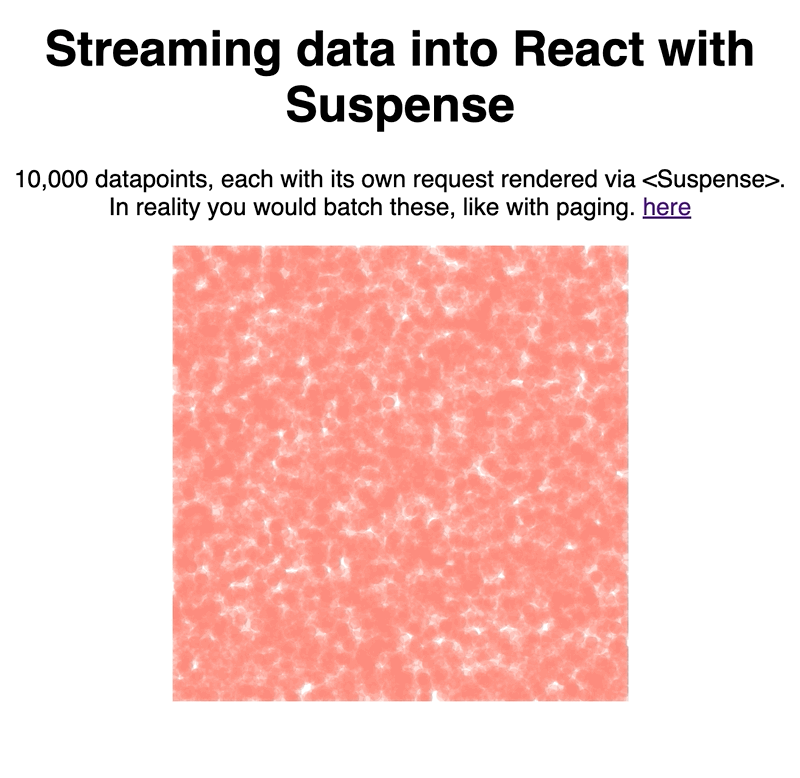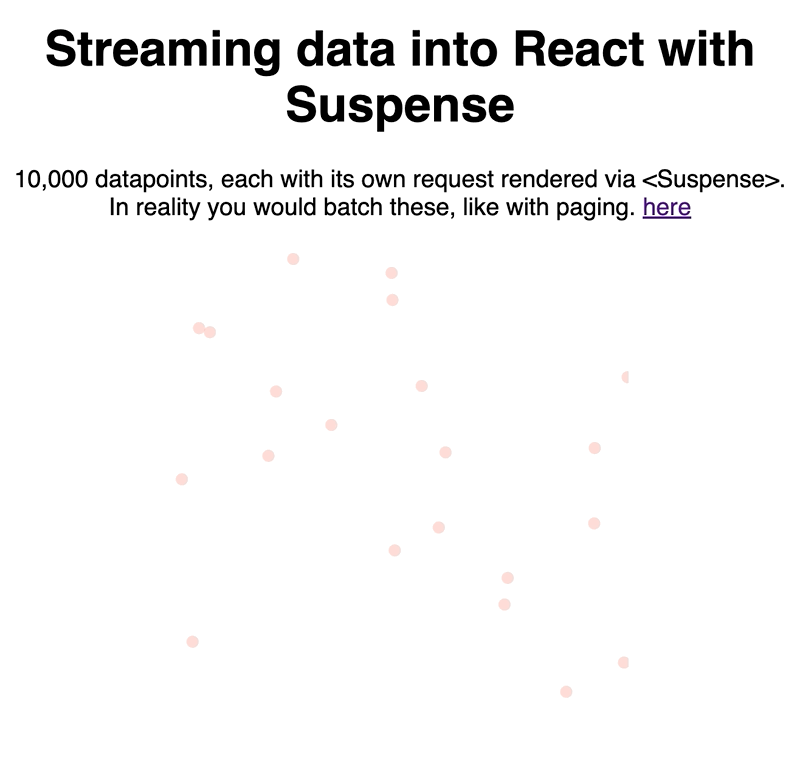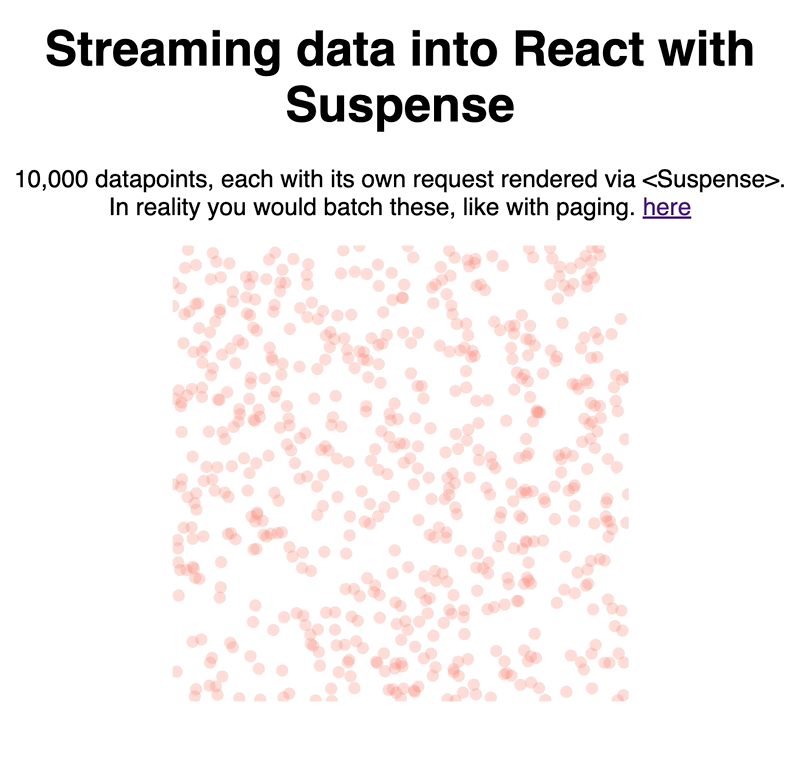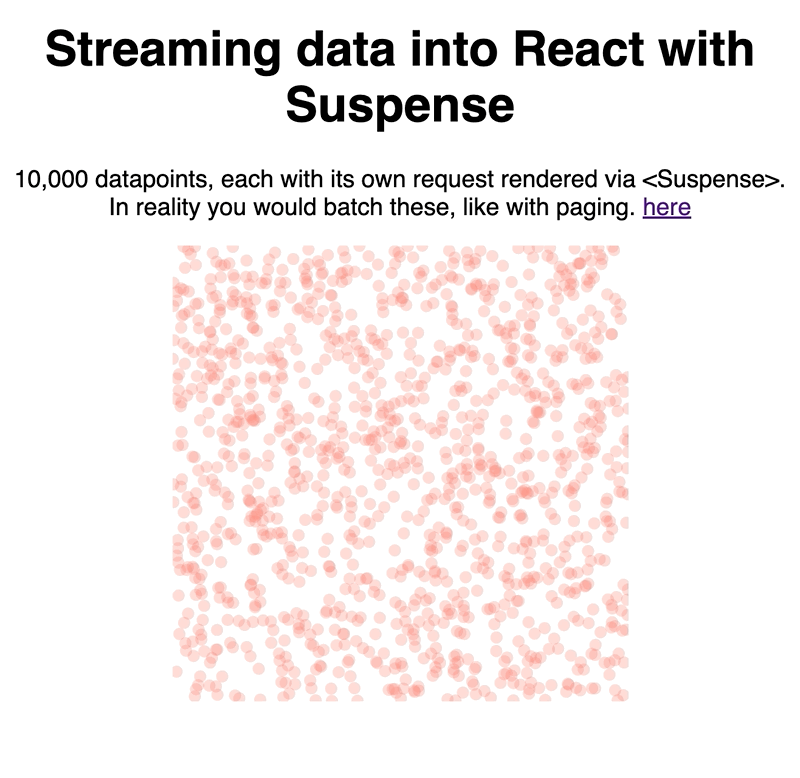
Our context is a D3 scatterplot because a) it looks pretty and b) reactfordataviz.com 😛
Don't worry, if you're not into dataviz. The same core concepts apply.
We created a fake data streaming API, rendered each unit of data with the new <Suspense /> component, and let React handle the rest. Works great.
Try it out here 👇
A fake streaming data API
We split our fake API into two endpoints:
- fetch a total count
- fetch datapoints one by one until done
A real world API analog would be an API that deals with large data. First you make a request for some meta data (counts, dates, ranges, etc), then page through the large dataset.
For simplicity and stress testing, we fetch each item individually. Timeouts simulate fetch() calls.

An API that understands
Those function calls simulate API requests. We have to wrap them in a way that <Suspense> understands.
I borrowed the promise wrapper that Dan Abramov uses in official docs on Suspense. You'd build something more robust for real life use. Or, if you're like me, wait for libraries to show up. 😇

The idea behind wrapPromise is to create a uniform interface for Suspense to hook into your promise. This way it can tell whether it's still waiting, there was an error, or you're ready to render.
I imagine this makes it easier to integrate with a variety of data fetching mechanisms. Wrapper makes them conform to Suspense's API.
Render-as-you-fetch
Once we've got the API wrappers set up, we can render our React app in parallel with fetching the data. In some cases even in parallel with fetching the code itself. (code splitting)

We start the request at top level, not inside an effect. This way it starts as soon as the file loads.
Presumably that's just before you're ready to render. The approach won't work if you're loading 500 pages all in a single bundle and only 1 of them is visible.
Top-level fetching assumes your router handles code splitting and loads only the files it needs.
To render our data without UI glitching, we use the <Suspense> component ✌️

We wrap everything in Suspense to show a loading state while we fetch meta data. The count in our case.
The <DataList> component itself tries to read from our API and render what it gets.

This is important and very easy to get wrong. Suspense goes around the component that's reading data.

Yeah, happened the very first time I tried to build with React Suspense without following the docs. You get that experiment in your inbox next week, it's super neat.
Now here's where it gets real fun: You can nest suspended components.
Notice how we're wrapping each <DataItem> in its own suspense?

That's because each item is in charge of its own API fetching. Seems kinda bonkers, but this new approach (also popular in GraphQL circles) is really powerful.
Each React component should take care of its own data fetching. The times when you had a central authority take care of all data are behind us. Edge computing is now. Even if just in our UI tree. 🦾

Each item hooks into its own index'd API promise that we created in fetchItem earlier.
items.read() returns an array of wrapped promises. [index] gets the one for this item. .read() waits for that promise to return some data.
The surrounding <Suspense> component handles suspending and fallback renders while this component waits for data to show up. Once data shows up, Suspense renders <DataItem> which uses a little D3 magic to translate [0, 1] numbers to a bigger scale and renders an SVG circle.
Streaming in batches
Now of course reading data one by one like that is slow.
Instead, you can use a paging approach and load a many data points at once. 100 worked pretty well with our fake API.
Rendering code looks the same, just gets an extra loop.

And we changed the fake API to return multiple datapoints per batch.

Fin
I encourage you to give React Suspense and concurrent mode in general a try. It's pretty great, almost ready for the real world, and it might make you rethink how you structure your apps.
Encouraging you to push data loading into the edges of your component tree seems like a particularly powerful pattern. Load data as close to where you're using it as possible.
Enjoy ❤️
~Swizec
Continue reading about Experimenting with the new React Concurrent mode
Semantically similar articles hand-picked by GPT-4
- Trying out React 18 Alpha
- Async React with NextJS 13
- React 18 and the future of async data
- Why I'm excited about React 18 – talk
- Towards a Gatsby+Suspense proof-of-concept
Learned something new?
Read more Software Engineering Lessons from Production
I write articles with real insight into the career and skills of a modern software engineer. "Raw and honest from the heart!" as one reader described them. Fueled by lessons learned over 20 years of building production code for side-projects, small businesses, and hyper growth startups. Both successful and not.
Subscribe below 👇
Software Engineering Lessons from Production
Join Swizec's Newsletter and get insightful emails 💌 on mindsets, tactics, and technical skills for your career. Real lessons from building production software. No bullshit.
"Man, love your simple writing! Yours is the only newsletter I open and only blog that I give a fuck to read & scroll till the end. And wow always take away lessons with me. Inspiring! And very relatable. 👌"

Have a burning question that you think I can answer? Hit me up on twitter and I'll do my best.
Who am I and who do I help? I'm Swizec Teller and I turn coders into engineers with "Raw and honest from the heart!" writing. No bullshit. Real insights into the career and skills of a modern software engineer.
Want to become a true senior engineer? Take ownership, have autonomy, and be a force multiplier on your team. The Senior Engineer Mindset ebook can help 👉 swizec.com/senior-mindset. These are the shifts in mindset that unlocked my career.
Curious about Serverless and the modern backend? Check out Serverless Handbook, for frontend engineers 👉 ServerlessHandbook.dev
Want to Stop copy pasting D3 examples and create data visualizations of your own? Learn how to build scalable dataviz React components your whole team can understand with React for Data Visualization
Want to get my best emails on JavaScript, React, Serverless, Fullstack Web, or Indie Hacking? Check out swizec.com/collections
Did someone amazing share this letter with you? Wonderful! You can sign up for my weekly letters for software engineers on their path to greatness, here: swizec.com/blog
Want to brush up on your modern JavaScript syntax? Check out my interactive cheatsheet: es6cheatsheet.com
By the way, just in case no one has told you it yet today: I love and appreciate you for who you are ❤️