Notes on A Relational Model of Data for Large Shared Data Banks
In 1970 a paper came out that changed the world of business computing – A Relational Model of Data for Large Shared Data Banks by E. F. Codd. It laid the ground work for modern databases.
Here's a copy of the paper with my scribbles.
Reading from 2022, the world described in Codd's paper is almost unimaginable. He talks about the biggest challenges in data management systems:
- data coupled to its program
- programs coupled to how data is stored
- zero flexibility when reading data
You had to write complex data transformation programs for any analysis that needed data in a new shape. Like seeing how many comments a user made on all articles, for example.
And forget about slapping more memory or disk space in your server when data grows too large. You'd have to re-optimize the entire data system to take advantage.
The only people who can imagine such a world are NoSQL users 😛
Benefits of the relational model
Codd suggests his relational model can support a system that gets around those common flaws. The paper does not go into implementation detail.
His core thesis is that:
- Data retrieval should be independent of its representation
- Data semantics shouldn't depend on storage concerns
- Different programs should be able to read the same data
The major insight from Codd's paper is that how you think about data – its abstract model – should be separate from how it's stored. Worry less about arrays and trees, think about what the data means.
Once you've separated data semantics from data representation, you unlock a wonderful possibility: An intermediate language can be constructed that asks the data system for data based on its properties, and the system figures out the details.
Instead of "Read 50 bytes from position A" you could say "Get article with id=2". We now call this a database.
The relational model
You've likely learned the relational model by osmosis if nothing else. It's the default way we think about data these days.
I found that Codd's original paper explained his model more clearly and concisely than all my college professors and years of experience. Maybe it's that I now know what to look for and 10 years ago it would fly right over my head.
Note that many things you do to optimize a relational database or make SQL easier to write do not fit Codd's original model. Denormalization, for example, goes strictly against everything Codd stood for.
However, SQL databases deviate from the relational model in many details, and Codd fiercely argued against deviations that compromise the original principles.
Every relation is a table
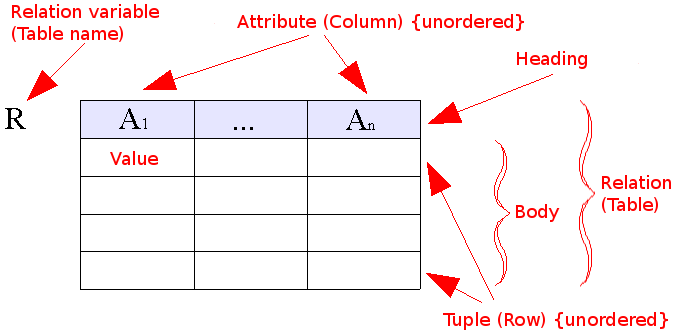
Codd describes data relations as named sets R of columns A where each column describes a nameable property of the relation. Each row holds a distinct tuple of column values.
Columns belong to a table, which means different tables can share columns of the same name. You can leverage this to represent relationships between domains. An identity column in R1 can be reused in R2 to mean "belongs to".
For example:
R1: user name 1 Swiz 2 Kiwi
R2: article title user 1 sdf 1 2 dfs 1
The user field in one table matches the user field in another. Now you can store user info about each article without multiplying user data.
This is known as the normal form:
- Has a primary key (no duplicates)
- Columns cannot be turned into a table (atomic)
Relations have set operations that produce relations
Because every relation is a set, standard set operations apply:
- permutations can shuffle the ordering of columns without changing their meaning. Useful for optimizing storage and reading patterns
- projections let you select partial data out of a table, conceptually this is a new relation
- joins bring the relational model's true power – you can create new relations by joining stored relations
For example if you join R1 and R2 from before, you get a new relation R':
R': article title user name 1 sdf 1 Swiz 2 dfs 1 Swiz
Because this is a relation, you can continue to do further joins, projections, permutations, and the rest.
- composition composes two relations much like a join, but unlike with a join, two relations are composable iff only one possible join exists. The example above was composable.
- restriction lets you get a subset of relation
Rbased on a relationS– like saying "Give me all rows that have these 2 column values
Redundancy and deriveability
Codd distinguishes between storage redundancy for performance reasons and redundancy in your data model.
It can be useful, for example, to store 2 copies of a table next to data that's often read together (like joining users on articles and on comments), but you don't want to replicate that in your data model. Let "the system" deal with those details.
He defines the concept of strong redundancy as a set of relations that can always be derived from other data. Like storing a count of comments with every article.
This can be useful for convenience, but is never required.
Weak redundancy means you can get the same information in multiple ways. This is unavoidable as your data grows in relationships.
No guarantees
The relational model on its own does not guarantee data consistency or anything like that. The system has to implement those at the cost of performance.
The model enables guarantees by creating followable rules and separating implementation details from data modeling concepts.
And that's bloody cool.
Cheers,
~Swizec
PS: a common problem with NoSQL, despite its many performance benefits, is that it breaks the separation between implementation details and data modeling. Best added to your stack once data usage patterns are known and speed matters.
Filed under: PapersDatabasesComputer ScienceData Modeling

