The trials and tribulations of a large-ish dataset
Hi 👋 you're reading a pretty old post! I started writing on here back in high school and this page may not reflect my current views. Recommend checking out related articles and categories down below, I've likely published more recent thoughts on this topic.
Last week I wrote a little script in node.js.
Its goal? GET ALL THE DATA!
The plan was to scrape a massive dataset off Github and do some analysis of programmers' working habits, at least the ones using Github that is. As such, the script was fairly simple - run a search query via the API, get page 1, 2, 3 ...
At 100 repositories per page with a round-trip of a few seconds and having to wait for an hour before being allowed to do more requests after every couple of hundred pages, the scraping job took the bigger part of a week. Occasionally the script would hang without getting a 403 error so I changed the query. That fixed it.
Sometimes it would crash - right after I'd gone to bed of course.
On Saturday morning I had a mongo database with a list of 513,900 repositories on a small EC2 instance. They were not guaranteed to be unique.
When N becomes a problem
The next step was going through the list of repositories and fetching punchcard data for each.

A core saying of practical computer science goes something like "Our O(N^5) algorithm sucks for large N, but N is usually less than 10"
Although not a very big dataset by most means, at half a million, it was enough to thwart my original approach of using Mongoose to handle my mongodb connection.
While Mongoose was great for writing, it failed completely at reading. Not exactly certain where the problem was, but running this sort of code quickly made my EC2 instance run out of memory:
models.repo.find({}, function (err, repos) {
repos.forEach(do_something);
});Where models.repo is the Schema for a repository.
So I was forced to ditch the relative comforts afforded by Mongoose and read my data the old fashioned way:
mongo.Db.connect(
format("mongodb://%s:%s/github-nightowls?w=1", 'localhost', 27017),
function(err, _db) {
var repos = _db.collection('repos'),
punchcards = _db.collection('punchcards');
repos.find().each(function (err, repo) {
// ...A lot more work, but it doesn't even show up as a blip on memory usage. My guess is that Mongoose was doing the wrong thing and didn't stream data right out of the database into my callback function, but was trying to keep it all in memory. Silly Mongoose.
There was one more step! Ensuring I only fetch punchcard data for unique repositories.
My first attempt was going through the data, adding each repository's username/name combination to a redis set, then following that set when fetching the punchcards. Remember, sets guarantee each member only shows up once.
Alas. After running a script for a few minutes - oh yes, did I mention it takes about 3 minutes just to read through the entire list of repositories? - it turns out the Redis set was so massive my attempts at reading it were to no avail. Ran out of memory before even doing anything serious.
This time I'm not sure it's node_redis's fault or Redis really cannot stream data out of sets as is reading them.
Eventually the algorithm to fetch punchards worked like this:
- Read object from Mongo
- Check Redis set if object already processed
- Fetch punchard
- Store punchcard
- Add new member to Redis set marking we've done this
Because of some inconsistencies in Github responses the first time I ran this, it crashed 5 minutes after I had gone to sleep.
Next run went much better!
Except the instance ran out of disk space after processing some 110k repositories and I only noticed after waiting 14 hours for everything to process. Kids, print your errors!
Third time is a charm and on Monday morning I had all the punchcards in a roughly 6 gigabyte mongo database. All 504,015 of them.
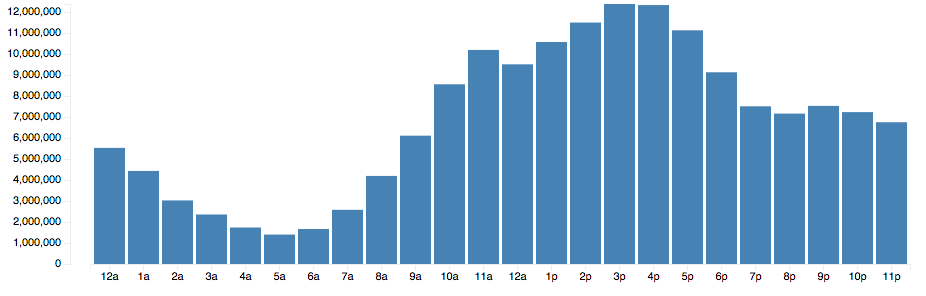
Luckily I had spent the previous day coding up a script calculating histograms - takes about 3 minutes to munch through the dataset - and playing with d3.js to make it look good.
In all, the dataset contains 164,509,270 commits. Only in punchcard form for now. This means I only have a 7x24 grid of buckets saying how many commits happened at that time.
Next step - finding a way to distinguish hobby and work projects to see if that affects the distribution of commit times. Wish me luck.
PS: If you want the dataset, send me an email and we can arrange something
PPS: for those interested, all the code for fetching my dataset is on github
Filed under: DatabaseGithubProgrammingBackend

