


Last week I wrote a little script in node.js.
Its goal? GET ALL THE DATA!
The plan was to scrape a massive dataset off Github and do some analysis of programmers' working habits, at least the ones using Github that is. As such, the script was fairly simple - run a search query via the API, get page 1, 2, 3 ...
At 100 repositories per page with a round-trip of a few seconds and having to wait for an hour before being allowed to do more requests after every couple of hundred pages, the scraping job took the bigger part of a week. Occasionally the script would hang without getting a 403 error so I changed the query. That fixed it.
Sometimes it would crash - right after I'd gone to bed of course.
On Saturday morning I had a mongo database with a list of 513,900 repositories on a small EC2 instance. They were not guaranteed to be unique.
When N becomes a problem
The next step was going through the list of repositories and fetching punchcard data for each.

A core saying of practical computer science goes something like "Our O(N^5) algorithm sucks for large N, but N is usually less than 10"
Although not a very big dataset by most means, at half a million, it was enough to thwart my original approach of using Mongoose to handle my mongodb connection.
While Mongoose was great for writing, it failed completely at reading. Not exactly certain where the problem was, but running this sort of code quickly made my EC2 instance run out of memory:
models.repo.find({}, function (err, repos) {
repos.forEach(do_something);
});
Where models.repo is the Schema for a repository.
So I was forced to ditch the relative comforts afforded by Mongoose and read my data the old fashioned way:
mongo.Db.connect(
format("mongodb://%s:%s/github-nightowls?w=1", 'localhost', 27017),
function(err, _db) {
var repos = _db.collection('repos'),
punchcards = _db.collection('punchcards');
repos.find().each(function (err, repo) {
// ...
A lot more work, but it doesn't even show up as a blip on memory usage. My guess is that Mongoose was doing the wrong thing and didn't stream data right out of the database into my callback function, but was trying to keep it all in memory. Silly Mongoose.
There was one more step! Ensuring I only fetch punchcard data for unique repositories.
My first attempt was going through the data, adding each repository's username/name combination to a redis set, then following that set when fetching the punchcards. Remember, sets guarantee each member only shows up once.
Alas. After running a script for a few minutes - oh yes, did I mention it takes about 3 minutes just to read through the entire list of repositories? - it turns out the Redis set was so massive my attempts at reading it were to no avail. Ran out of memory before even doing anything serious.
This time I'm not sure it's node_redis's fault or Redis really cannot stream data out of sets as is reading them.
Eventually the algorithm to fetch punchards worked like this:
- Read object from Mongo
- Check Redis set if object already processed
- Fetch punchard
- Store punchcard
- Add new member to Redis set marking we've done this
Because of some inconsistencies in Github responses the first time I ran this, it crashed 5 minutes after I had gone to sleep.
Next run went much better!
Except the instance ran out of disk space after processing some 110k repositories and I only noticed after waiting 14 hours for everything to process. Kids, print your errors!
Third time is a charm and on Monday morning I had all the punchcards in a roughly 6 gigabyte mongo database. All 504,015 of them.
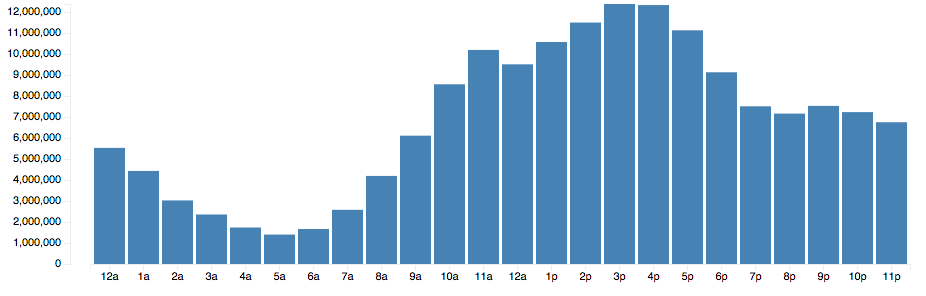
Luckily I had spent the previous day coding up a script calculating histograms - takes about 3 minutes to munch through the dataset - and playing with d3.js to make it look good.
In all, the dataset contains 164,509,270 commits. Only in punchcard form for now. This means I only have a 7x24 grid of buckets saying how many commits happened at that time.
Next step - finding a way to distinguish hobby and work projects to see if that affects the distribution of commit times. Wish me luck.
PS: If you want the dataset, send me an email and we can arrange something
PPS: for those interested, all the code for fetching my dataset is on github
Continue reading about The trials and tribulations of a large-ish dataset
Semantically similar articles hand-picked by GPT-4
- Quick scatterplot tutorial for d3.js
- Chrome's console.log is the slowest
- My old code is atrocious
- Sabbatical week day 2: I fail at Octave
- 90% of performance is data access patterns
Learned something new?
Read more Software Engineering Lessons from Production
I write articles with real insight into the career and skills of a modern software engineer. "Raw and honest from the heart!" as one reader described them. Fueled by lessons learned over 20 years of building production code for side-projects, small businesses, and hyper growth startups. Both successful and not.
Subscribe below 👇
Software Engineering Lessons from Production
Join Swizec's Newsletter and get insightful emails 💌 on mindsets, tactics, and technical skills for your career. Real lessons from building production software. No bullshit.
"Man, love your simple writing! Yours is the only newsletter I open and only blog that I give a fuck to read & scroll till the end. And wow always take away lessons with me. Inspiring! And very relatable. 👌"

Have a burning question that you think I can answer? Hit me up on twitter and I'll do my best.
Who am I and who do I help? I'm Swizec Teller and I turn coders into engineers with "Raw and honest from the heart!" writing. No bullshit. Real insights into the career and skills of a modern software engineer.
Want to become a true senior engineer? Take ownership, have autonomy, and be a force multiplier on your team. The Senior Engineer Mindset ebook can help 👉 swizec.com/senior-mindset. These are the shifts in mindset that unlocked my career.
Curious about Serverless and the modern backend? Check out Serverless Handbook, for frontend engineers 👉 ServerlessHandbook.dev
Want to Stop copy pasting D3 examples and create data visualizations of your own? Learn how to build scalable dataviz React components your whole team can understand with React for Data Visualization
Want to get my best emails on JavaScript, React, Serverless, Fullstack Web, or Indie Hacking? Check out swizec.com/collections
Did someone amazing share this letter with you? Wonderful! You can sign up for my weekly letters for software engineers on their path to greatness, here: swizec.com/blog
Want to brush up on your modern JavaScript syntax? Check out my interactive cheatsheet: es6cheatsheet.com
By the way, just in case no one has told you it yet today: I love and appreciate you for who you are ❤️