


Semantic search used to be a major feat of engineering. This weekend I built one in 2 hours of tinkering with the OpenAI API 🤯
Check this out:

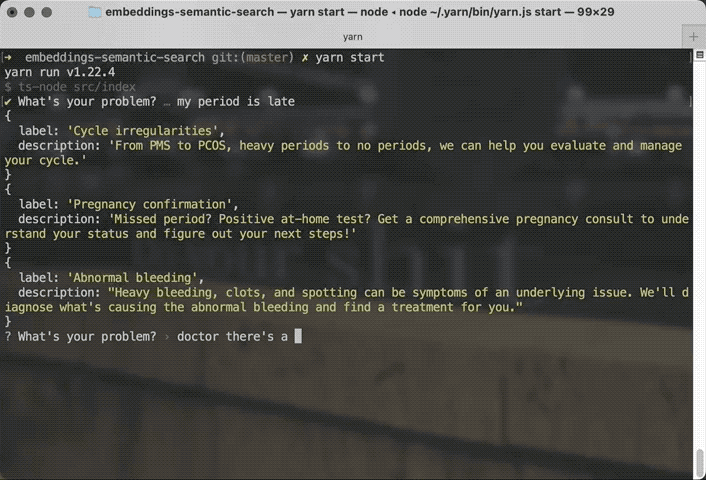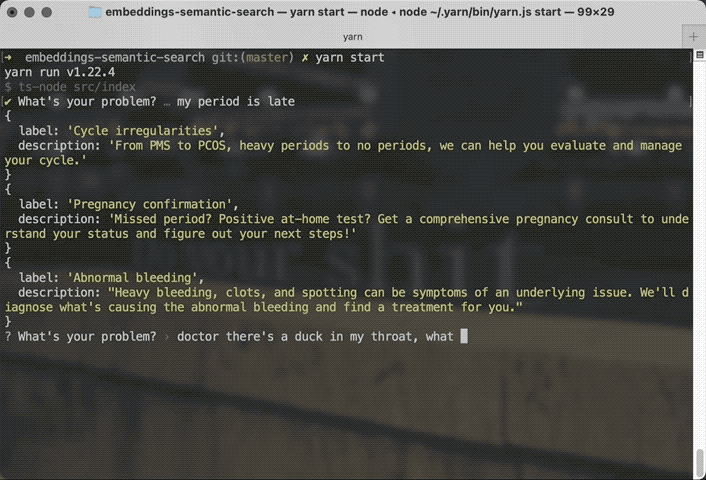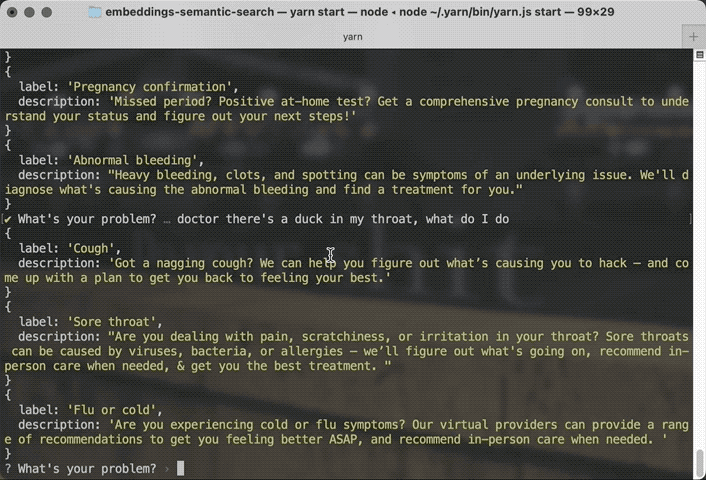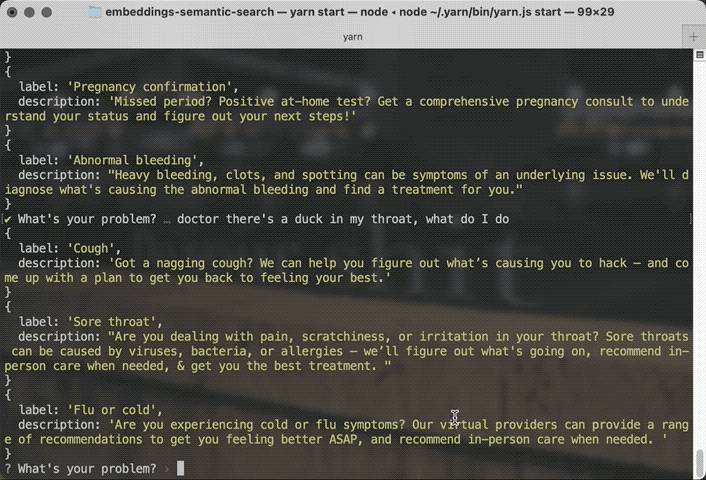
You say "my period is late" and the search is smart enough to recommend Cycle Irregularities and Pregnancy Confirmation as top results. If you say there's a duck stuck in your throat, the search can figure that out too.
It blows me away that a schmuck like me can build this in 2 hours because we live in the future. When I last looked at semantic search in the early 2010's I couldn't even get past the setup instructions for Solr, a natural language processing server, and Lucene, the library it's built on.
Here's how it works:
- Compute embedding vectors for your data
- Compute embedding vector for your query
- Sort vectors by similarity
Semantic search with full support for synonyms, metaphors, typos, and similes falls out thanks to the vast background info encoded in the large language model, LLM.
Compute embedding vectors for your data
Before you can search, you need embeddings for the documents you want to search through. I put mine in a CSV.
The code below reads a 2-column CSV – label and description – and outputs a 3-column CSV with an embedding column. Using the csv library to parse and stringify CSV data.
async function addEmbeddingsToCSV() {
const columns = ["label", "description", "embedding"]
const readStream = fs
.createReadStream("./data/input.csv")
.pipe(csv.parse({ from_line: 2 }))
const writeStream = fs.createWriteStream("./data/input_with_embeddings.csv")
const stringifier = csv.stringify({ header: true, columns })
for await (const row of readStream) {
const [label, description] = row
const embedding = await getEmbedding(
`Title: ${label}; Content: ${description}`
)
console.log(label)
stringifier.write([label, description, embedding])
}
stringifier.pipe(writeStream)
console.log("done")
}
The cookbook made it look like encoding your input as Title: ..; Content: .. was important. Probably because GPT was trained on articles from the web.
The getEmbedding function at the core of our code makes an API request to OpenAPI:
async function getEmbedding(input: string) {
const embedding = await openai.createEmbedding({
model: "text-embedding-ada-002",
input,
})
return embedding.data.data[0].embedding
}
Embeddings won't change in the future so it's best to pre-compute this separately and save the vectors. You'll want to use a vector database for a production app. I've heard the pgvector plugin for Postgres works great.
Compute embedding vector for your query
Getting a vector for your query is more of the same:
const { search } = await prompts({
type: "text",
name: "search",
message: "What's your problem?",
})
const needle = await getEmbedding(search)
Get search string from user, compute the embedding.
Sort vectors by similarity
This is where the search happens. You're looking for "How far away from the input data is the user's query?"
for (const item of haystack) {
item.similarity = cosineSimilarity(needle, item.embedding)
}
haystack.sort((a, b) => b.similarity - a.similarity)
Compute vector cosine similarities and sort the haystack. The top few matches are your search results.
I used the compute-cosine-similarity JavaScript library. For production use you'd want to let your vector database handle this part.
What is an embedding vector
I don't know. My understanding is that it's a vector that "embeds" your string in the LLM's vast N-dimensional understanding of training data.
Like an index that says "here it is in the brain".
The part I don't get is how come embeddings can have 1536 dimensions when the LLM itself has billions of parameters. Means the embedding can't be just a list of activated neurons 🤔
Cheers,
~Swizec
PS: I followed OpenAI's wonderful cookbook example to build this
Continue reading about Build semantic search in an afternoon? Yep 🤯
Semantically similar articles hand-picked by GPT-4
- Similarity search with pgvector and Supabase
- How I Added a Related Articles Feature on Swizec.com Using GPT-4 Embeddings
- Programming in Markdown
- Building apps with OpenAI and ChatGPT
- How to start playing with generative AI
Learned something new?
Read more Software Engineering Lessons from Production
I write articles with real insight into the career and skills of a modern software engineer. "Raw and honest from the heart!" as one reader described them. Fueled by lessons learned over 20 years of building production code for side-projects, small businesses, and hyper growth startups. Both successful and not.
Subscribe below 👇
Software Engineering Lessons from Production
Join Swizec's Newsletter and get insightful emails 💌 on mindsets, tactics, and technical skills for your career. Real lessons from building production software. No bullshit.
"Man, love your simple writing! Yours is the only newsletter I open and only blog that I give a fuck to read & scroll till the end. And wow always take away lessons with me. Inspiring! And very relatable. 👌"

Have a burning question that you think I can answer? Hit me up on twitter and I'll do my best.
Who am I and who do I help? I'm Swizec Teller and I turn coders into engineers with "Raw and honest from the heart!" writing. No bullshit. Real insights into the career and skills of a modern software engineer.
Want to become a true senior engineer? Take ownership, have autonomy, and be a force multiplier on your team. The Senior Engineer Mindset ebook can help 👉 swizec.com/senior-mindset. These are the shifts in mindset that unlocked my career.
Curious about Serverless and the modern backend? Check out Serverless Handbook, for frontend engineers 👉 ServerlessHandbook.dev
Want to Stop copy pasting D3 examples and create data visualizations of your own? Learn how to build scalable dataviz React components your whole team can understand with React for Data Visualization
Want to get my best emails on JavaScript, React, Serverless, Fullstack Web, or Indie Hacking? Check out swizec.com/collections
Did someone amazing share this letter with you? Wonderful! You can sign up for my weekly letters for software engineers on their path to greatness, here: swizec.com/blog
Want to brush up on your modern JavaScript syntax? Check out my interactive cheatsheet: es6cheatsheet.com
By the way, just in case no one has told you it yet today: I love and appreciate you for who you are ❤️