


A while back I shared how you can build semantic search in an afternoon with modern tech. Pretty sweet, right?
That article used a large CSV file as its "database", which is about the slowest most inefficient tool you can use. Reading a huge CSV file into memory, sorting all rows, then picking 5 and throwing away everything else 😂 You can see the slowness of that technique in my SwizBot built on swizec.com articles. Every response takes forever.
Last week I tried something faster – pgvector on Supabase!
PS: you can read and share this online
What we're building
That gif shows a similarity search between conference attendees. We're building a tool for AI Engineer Summit to make the conference more interesting.
Everyone coming to the conference answers a few questions. What are you looking for, what gets you fired up about AI, why are you here?
We find people with matching interests and, if you both say yes, make a warm intro. Go talk to Swizec about building prototypes with LLMs. It's gonna be great.
Here's a mockup of what the UI will look like. Simon's building that single-handedly because he's awesome ❤️

What's pgvector? Supabase??
pgvector is a Postgres plugin that adds vector support to Postgres, the best general database out there. It adds a couple new query operators and lets you efficiently store and query vectors as part of a regular database table.
Supabase is a hosted Postgres provider popular with the serverless crowd. Supabase manages the hosting, offers a nice management UI, and lets you access data through their SDK or a regular Postgres client using SQL queries.
Building a pgvector similarity search
I built all the code you're about to see using markdown programming with ChatGPT. You could optimize parts of the code by hand, but it's fine for the amount of data we've got.
The technique works in 3 steps:
- Prep the Supabase DB for pgvector
- Compute and store embeddings for every attendee's responses
- Find similar attendees with a vector similarity search
All based on OpenAI embeddings. It cost me about $1 to run this for a few thousand rows of data.
Prep the Supabase DB for pgvector
Supabase comes pre-installed with the pgvector plugin. You have to enable the plugin and create an embeddings table.
Query to enable the plugin:
CREATE EXTENSION vector;
Any Postgres server should support this after you install pgvector on the system.
With pgvector enabled, you create an embeddings table like this:
create table
public."UserEmbedding" (
id serial,
"userProfileId" text not null,
embedding extensions.vector null,
constraint UserEmbedding_pkey primary key (id),
constraint UserEmbedding_userProfileId_key unique ("userProfileId"),
constraint UserEmbedding_userProfileId_fkey foreign key ("userProfileId") references "UserProfile" (id) on delete restrict
) tablespace pg_default;
The query creates a UserEmbedding table with an auto-incrementing id field, a unique userProfileId field that points at the UserProfile table, and an embedding vector field.
We'll add more vector columns in the future so we can run different types of comparisons. The embedding column name needs a better name too.
Compute and store embeddings for every attendee
We'll need embedding vectors for each attendee to run similarity queries. Working with the assumption that giving similar answers to survey questions means you have similar interests.
The code first connects to the DB and inits an OpenAI client.
const { Client } = require("pg")
const OpenAI = require("openai")
const db = new Client({
connectionString: process.env.SUPABASE_URL,
})
const openai = new OpenAI(process.env.OPENAI_API_KEY)
await db.connect()
Then it reads a list of users and their answers from the DB:
const res = await db.query(
`SELECT * FROM "UserProfile" JOIN "SurveyAnswer" ON "UserProfile".id = "SurveyAnswer"."userProfileId"`
)
The result is an array of rows, one per survey answer. Each user answers multiple questions so we'll process them multiple times. It's fine :)
For each user we:
- Collect all answers into a string
- Compute an embedding
- Upsert the embedding into
UserEmbeddings
for (const row of res.rows) {
const answers = res.rows
.filter((r) => r.userProfileId === row.userProfileId)
.map((r) => `${r.question}: ${r.answer}`)
.join(" ")
console.log(`Processing ${row.userProfileId}...`)
const embeddingRes = await openai.embeddings.create({
model: "text-embedding-ada-002",
input: answers,
})
const embedding = embeddingRes.data[0].embedding
const upsertQuery = `
INSERT INTO "UserEmbedding" ("userProfileId", embedding)
VALUES ($1, $2)
ON CONFLICT ("userProfileId")
DO UPDATE SET embedding = EXCLUDED.embedding
`
await db.query(upsertQuery, [row.userProfileId, JSON.stringify(embedding)])
}
You have to stringify the embedding vector because pgvector expects vectors to start with an [ and the node-postgres library converts JavaScript arrays into Postgres sets by default. Those start with {.
Using ON CONFLICT DO UPDATE turns our insert into an upsert.
Even better would've been to avoid processing each user multiple times ¯_(ツ)_/¯
Run a vector similarity search
Once you've got a database table populated with vectors, you can leverage the full power of pgvector. The biggest benefit is that you can use JOINs to read your other data all in 1 query.
ChatGPT came up with this function to find the 5 most similar attendees to a given userProfileId. The function reads and prints matches and their answers so we can evaluate the result.
const findSimilarUsers = async (userProfileId) => {
try {
await client.connect()
// Find the top 5 nearest neighbors based on embeddings
const nearestQuery = `
SELECT * FROM "UserEmbedding"
WHERE "userProfileId" != $1
ORDER BY embedding <-> (
SELECT embedding FROM "UserEmbedding" WHERE "userProfileId" = $1
) LIMIT 5;
`
const res = await client.query(nearestQuery, [userProfileId])
const similarUsers = res.rows
for (const user of similarUsers) {
const infoQuery = `
SELECT "UserProfile".id, "UserProfile"."firstName", "UserProfile"."lastName", "SurveyAnswer".question, "SurveyAnswer".answer
FROM "UserProfile"
INNER JOIN "SurveyAnswer" ON "UserProfile".id = "SurveyAnswer"."userProfileId"
WHERE "UserProfile".id = $1;
`
const userInfo = await client.query(infoQuery, [user.userProfileId])
console.log(`First Name: ${userInfo.rows[0].firstName}`)
console.log("Survey Answers:")
userInfo.rows.forEach((row) => {
console.log(` ${row.question}: ${row.answer}`)
})
console.log("--------------------------------------------------")
}
} catch (err) {
console.error("Error:", err)
} finally {
await client.end()
}
}
First query holds the pgvector magic. That <-> operator means euclidean distance between vectors. You can use <#> for negative inner product and <=> for cosine distance.
That means you can read SELECT * FROM "UserEmbedding" WHERE ... ORDER BY embedding <-> (SELECT embedding ...) LIMIT 5 as select all properties from the first 5 results from UserEmbedding where userProfileId isn't the input ordered by distance between embedding vectors in UserEmbedding.
And it's fast! 😍
If default performance isn't fast enough for you, pgvector supports indexing on vector columns. That gives you another few orders of magnitude.
Biggest benefit of pgvector
I've heard rumors that "pgvector doesn't scale", but I think that kicks in once you have millions of rows. Most of us don't have that problem.
The biggest benefit is that pgvector lets you keep vector data next to your other business data. This allows you to run JOINs (like you see above) and all sorts of queries without worrying about access patterns or writing additional code. A great benefit in the beginning of any project!
Keeping data together also cuts down on overhead. Any performance benefit you get from using a pure vector database is likely to be overshadowed by what you lose in pulling from multiple data sources and joining data with code.
At least while your data is small.
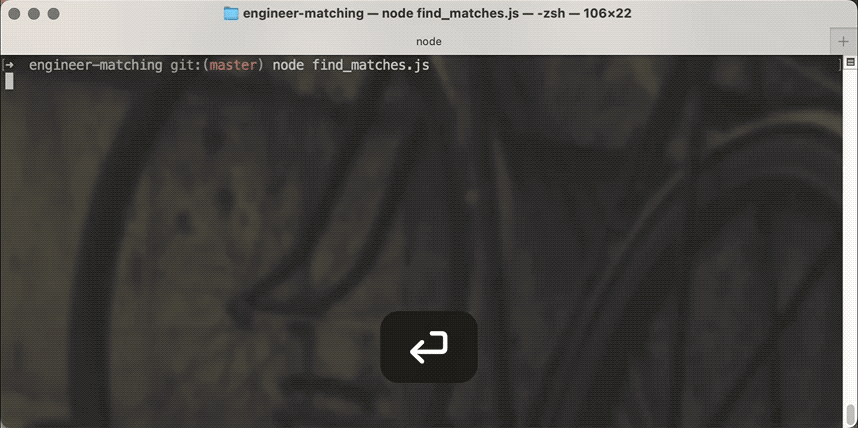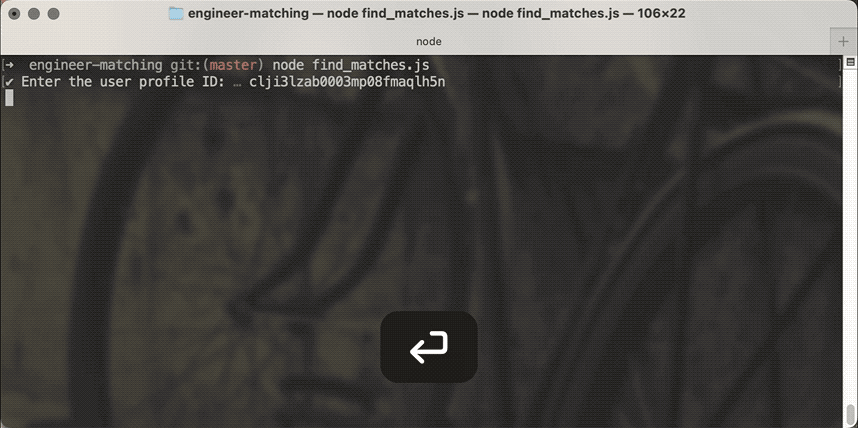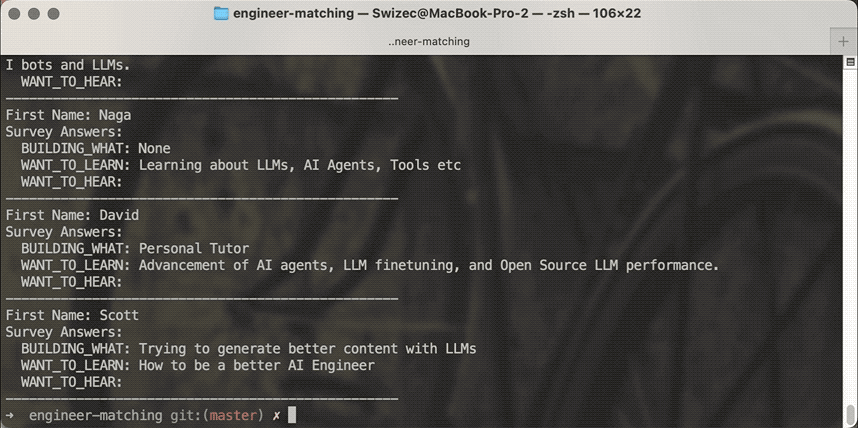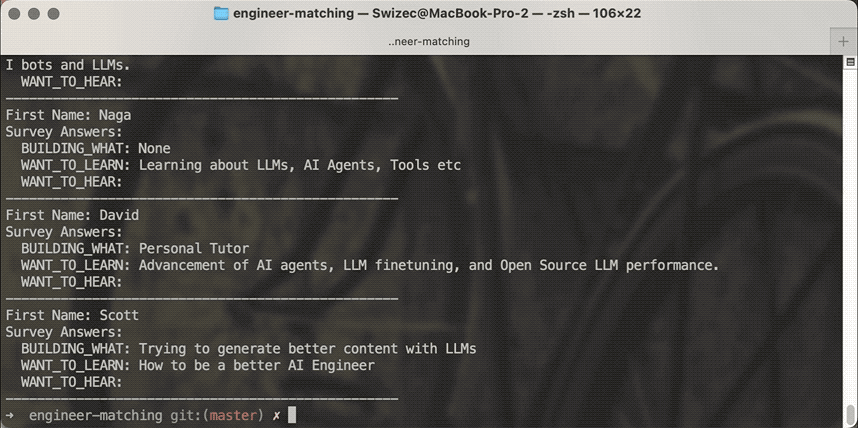
The result
Using me as an example, you get these matches:
First Name: Rajeev Survey Answers: BUILDING_WHAT: Getting started on the AI engineering journey! WANT_TO_LEARN: Using LLMs for solving business problems WANT_TO_HEAR:
First Name: Garth Survey Answers: BUILDING_WHAT: WANT_TO_LEARN: Practical ways to build AI flows to help businesses become more successful by utilizing AI bots and LLMs. WANT_TO_HEAR:
First Name: Naga Survey Answers: BUILDING_WHAT: None WANT_TO_LEARN: Learning about LLMs, AI Agents, Tools etc WANT_TO_HEAR:
First Name: David Survey Answers: BUILDING_WHAT: Personal Tutor WANT_TO_LEARN: Advancement of AI agents, LLM finetuning, and Open Source LLM performance. WANT_TO_HEAR:
First Name: Scott Survey Answers: BUILDING_WHAT: Trying to generate better content with LLMs WANT_TO_LEARN: How to be a better AI Engineer WANT_TO_HEAR:
Looks good. As a fellow newb, I'd love to chat with these folks. 👍
Will I see you at the conference? Heck I'll buy you a beer if we get matched ... or even if we don't, the beer's free ;)
Cheers,
~Swizec
Continue reading about Similarity search with pgvector and Supabase
Semantically similar articles hand-picked by GPT-4
- Build semantic search in an afternoon? Yep 🤯
- How I Added a Related Articles Feature on Swizec.com Using GPT-4 Embeddings
- Using AI to spark connections at a conference
- Logging 1,721,410 events per day with Postgres, Rails, Heroku, and a bit of JavaScript
- Programming in Markdown
Learned something new?
Read more Software Engineering Lessons from Production
I write articles with real insight into the career and skills of a modern software engineer. "Raw and honest from the heart!" as one reader described them. Fueled by lessons learned over 20 years of building production code for side-projects, small businesses, and hyper growth startups. Both successful and not.
Subscribe below 👇
Software Engineering Lessons from Production
Join Swizec's Newsletter and get insightful emails 💌 on mindsets, tactics, and technical skills for your career. Real lessons from building production software. No bullshit.
"Man, love your simple writing! Yours is the only newsletter I open and only blog that I give a fuck to read & scroll till the end. And wow always take away lessons with me. Inspiring! And very relatable. 👌"

Have a burning question that you think I can answer? Hit me up on twitter and I'll do my best.
Who am I and who do I help? I'm Swizec Teller and I turn coders into engineers with "Raw and honest from the heart!" writing. No bullshit. Real insights into the career and skills of a modern software engineer.
Want to become a true senior engineer? Take ownership, have autonomy, and be a force multiplier on your team. The Senior Engineer Mindset ebook can help 👉 swizec.com/senior-mindset. These are the shifts in mindset that unlocked my career.
Curious about Serverless and the modern backend? Check out Serverless Handbook, for frontend engineers 👉 ServerlessHandbook.dev
Want to Stop copy pasting D3 examples and create data visualizations of your own? Learn how to build scalable dataviz React components your whole team can understand with React for Data Visualization
Want to get my best emails on JavaScript, React, Serverless, Fullstack Web, or Indie Hacking? Check out swizec.com/collections
Did someone amazing share this letter with you? Wonderful! You can sign up for my weekly letters for software engineers on their path to greatness, here: swizec.com/blog
Want to brush up on your modern JavaScript syntax? Check out my interactive cheatsheet: es6cheatsheet.com
By the way, just in case no one has told you it yet today: I love and appreciate you for who you are ❤️